Developer Guide
Learn details about file formats and source code.
File Format Description
This chapter describes the file formats MD3, MDC, MDS, MDM/MDX and TAG. It contains links to the unofficial specs, an overview of the most common data, and some words on most common encoding schemes.
File Format Specifications
Here you can find the unofficial file format specifications for MD3, MDC, MDS, MDM/MDX and TAG.
Data Overview
MD3, MDC, MDS, and MDM/MDX are indexed triangle meshes. The main data fields are surfaces, tags, bones, bounding volumes, and level of detail. However, there are differences among the formats and not all the formats include the same information.
Surfaces
Surfaces make up the basic model. They are described by geometry, color and animation data.
Geometry of a surface is described by grouping vertices into a triangle. Triangles are then grouped into a surface.
Colorization of a surface is done by defining UV-maps and references to shaders. The UV-maps are used to color surfaces with solid color from a 2D image. Shaders manipulate surface properties. These properties define how the surface interacts with light sources present in a scene. Additionally vertex normals manipulate the shading of a surface.
Animation of a surface is different per format. MD3 and MDC store vertex positions per frame. This animation technique is also known as "morph target animation". The way it works is that for each key frame a series of vertex positions is stored. Between two successive frames, the vertices are then interpolated between the positions. MD3 stores absolute vertex positions as opposed to MDC, which can store offsets relative to a base frame
MDS and MDM/MDX store vertex location and normal values in relation to a skeleton. This animation technique is also known as "skeletal animation". The way it works is that for each key frame the vertex location and normal values are influenced-by/weighted-against the location and orientation values of 1 or more bones. Thus, only bones contain animation data while vertex values are stored once in a special model pose called "binding pose".
Tags
Tags are used to attach external models to a model. Attachment means that the external models origin aligns itself with the models tag location and orientation. As the external model is parented to the tag (nested in tag space), any animation of the tag will also affect the external model.
Domain specific scripts tell the engine which external models to attach to a given tag. These scripts are either located in mapscript files (attachtotag command) or .skin files. Sometimes they are also hard coded.
An example use case is a hat model (defined separately) attached to a head model. This way, characters can be assembled with different looks without having to duplicate their model definitions. Tags therefore support reuse.
Another example use case is that of a tank turret model attached to a tank model. Instead of having a shooting animation (rotate turret left, shoot, rotate turret right) be recorded as vertex positions across several key-frames inside a single model, a tag can be used to control the shooting animation of a separated model. This safes memory, as the tags animation data most likely takes much less space compared to the animation data of the tank turret inside a single model.
However, reuse and memory savings are traded against loss in performance. Vertex positions of the external models have to be recalculated against the current frame tags location and orientation.
Tags are specified in relation to a bone or not. In case they are parented to a bone, the bone animation data determines the animation of the tag. There are tags with an offset in location and orientation to a bone, or there are tags with no such offset. In the latter case these tags are more or less the bones themselves.
Bones
Bone data is used on the formats MDS and MDM/MDX. Bones are arranged in a hierarchy, but their data is actually not defined in any parent bone space. For more information on skeletal animation a good book is recommended, but a starting point may also be Wikipedia.
Bounding Volumes
Each format includes bounding volume information. This data is stored each frame and is made up of an axially-aligned bounding box and a bounding sphere.
Level of Detail
MDS and MDM/MDX store their level of detail data in the same file as the rest of the data. The method used is a progressive mesh algorithm. This algorithm is described in a publication by Stan Melax.
MD3 and MDC in turn the well known discrete method of storing level of detail. There are 3 detail levels for a model. The less detailed models are usually stored in the same directory as the highest detail model.
Encoding Schemes
MD3, MDC, MDS, and MDM/MDX use different encoding schemes when writing their data to file. This mostly concerns location and orientation values.
What all formats have in common is that they store their data as a byte stream to file. All types are encoded in little endian byte order. The coordinate system convention is right handed: x points forward, y points left, z points up.
Type Compression
Type compression is found nearly everywhere. It was probably a major design criteria in order to save both disk and in-memory footprint. If you know more on why it was used so often back then, please shoot me an E-Mail.
For example the location values for nearly all vertices are type compressed. Here the actual type is a float, but its encoding on disk is a 16-bit integer.
In order to convert back and forth between the encoded type value and the type value itself, you need to scale the value by a predefined constant. This constant is defined in the source code of the file readers of the engine.
The scale value in turn also defines certain limits. For example a vertex location in MD3 (writing this out of my head, but you can always check it by doing the math) can never exceed an absolute value of 512.0 units. This is because the scale value linearly maps the integer value to a range of floats.
Offset Compression
Offset compression takes the idea of type compression one step further. It is used by MDC only.
For it to work, MDC defines two types of frames: base frames and compressed frames. Base frames do not use offset compression. If a base frame is used, then the encoding scheme used for the vertex values is the same as with MD3: that means a type compressed 16-bit integer is used. If a compressed frame is used, then MDC compresses a small float value (the offset value) down to an 8-bit integer (offset compression). The offset value is defined relative to the value in its base frame.
Matrix Representation
Rotation matrices are used in MD3 to encode the orientation of tags. There is no type compression used on those values. The byte streams first 3 bytes encode the x-basis vector, and so on.
Tait-Bryan Angles
Another way to encode orientation is with Tait-Bryan angles. This representation technique also saves space on disk and in-memory. Additionally, the values are type compressed. Their unencoded type values range from 0 to 360. The first byte in the field encodes the pitch value, the second one the yaw value, and the third is the roll value. In terms of actually converting this to a rotation matrix, the values are applied in this order: roll, pitch, yaw. The convention is to rotate around the moving coordinate systems (intrinsic).
Spherical Coordinates
Spherical coordinates are used to define the direction of a vertex normal. It is most easy to just think of them in terms of Tait-Bryan angles, but without a roll. The values in the fields are again type compressed. The values are encoded into two 8-bit fields. The first byte encodes the pitch value, the second byte encodes the yaw value. The rotation is performed starting with the upwards-vector. Rotation order is: pitch, yaw (intrinsic).
Quick Comparison
The major difference in file formats is their animation technique. MD3 and MDC uses morph target animation. MDS and MDM/MDX uses skeletal animation. MD3 and MDC can be further differentiated in that MDC additionally compresses its animation data by using offset compression.
Tags are another major difference. MD3 and MDC store tag location and orientation values per frame and in model space. MDS and MDM/MDX store their tag values relative to a bone. MDS directly uses the bone location and orientation values for tags. MDM/MDX defines its tag values in bone space as an offset.
Source Code Description
This chapter gives a high-level overview of the the source code.
Introduction to MDI
Everything in the source code is based on the MDI (Model Definition Interchange) format. It is a custom data interchange format created for abstracting the data of all other formats. It is a superset of MD3, MDC, MDS, MDM/MDX and TAG formats and a subset of Blenders .blend format.
The reason it was introduced is to have a scalable source code architecture by reducing the time spent on developing and maintaining converters. To understand this, let's take a look at a simple example, which we are going to extend by introducing more and more formats into the system.
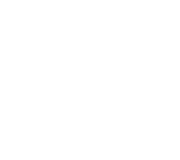
In the diagram above we have two formats called A and B. We can see that each format must have a file back end. We can also see that if we want to convert between the formats we would need to convert into each direction. That amounts for two converters: one from A to B and one from B to A.
Let's add another format to see how the number of converters increase:
The number of converters is now 6. Let's add yet another format:
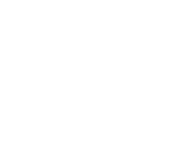
The number of converters is now 12. We can derive a pattern from this. Each new format requires a certain amount of converters to be added. That amount is 2 times the number of already existing formats.
So even for a small amount of formats, a system of interchangable model formats like this would not be scalable. There needs to be an abstracted data format, which would be able to contain all the data and which could be passed around. Thus MDI was born. It decouples the conversion process by being a common medium of data exchange. Of course, there are interchange formats such as .fbx or .collada. But they all lack the specific features required for some data fields in the model formats for RtCW and W:ET.
Source Code Architecture
For reasons explained in the previous chapter, the source code is based on a custom interchange format called MDI. The following graph depicts the architecture.
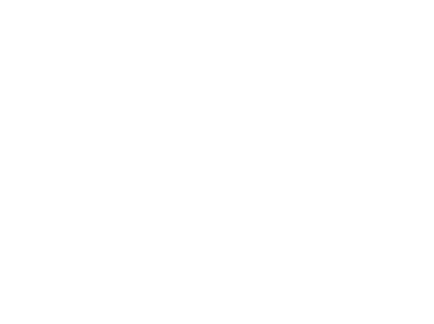
Each model format was developed in a special package of modules called component. Each component contains a reader, a writer, and a converter. The readers and writers deal with their respective formats native encoding schemes. The converters transform the native data to and from MDI.

Now, if a new format is going to be integrated into the system, all that is needed to do is write a reader and writer, as well as a single converter to and from MDI. Of course, this is only half of the truth, as some model formats might have features MDI does not have.
Background Material
As keyword-list:
- Indexed triangle meshes
- Cartesian coordinate system
- Vectors
- Matrices
- Euler angles
- Tait-Bryan Angles
- Spherical coordinate system
- Coordinate Space Transformations
- Spherical to cartesian or matrix to euler
- Texture-Mapping
- Gouraud shading
- Rendering equation
- Morph target animation
- Skeletal animation
- Progressive meshes
Specifics of the formats and helpful publications:
- PhaethonH. "Description of MD3 Format". July 2011.
- Prinz, Wolfgang. "The MDC File Format". May 2004.
- Cookson, Chris. "Unofficial Return to Castle Wolfenstein MDS File Format Spec v1.0". 2002.
- Ikonatto. "MDM MDX unofficial specification". ~2002.
- Melax, Stan. "A Simple, Fast, and Effective Polyong Reduction Algorithm". November 1998.
- Slabaugh, Gregory: "Computing Euler angles from a rotation matrix". January 1999.
- Dunn, Fletcher and Parberry, Ian. "3D Math Primer for Graphics and Game Development (2nd Edition)". November 2011.